vue项目地址增改删选中等功能
本文共 209 字,大约阅读时间需要 1 分钟。
首先地址列表,渲染数据
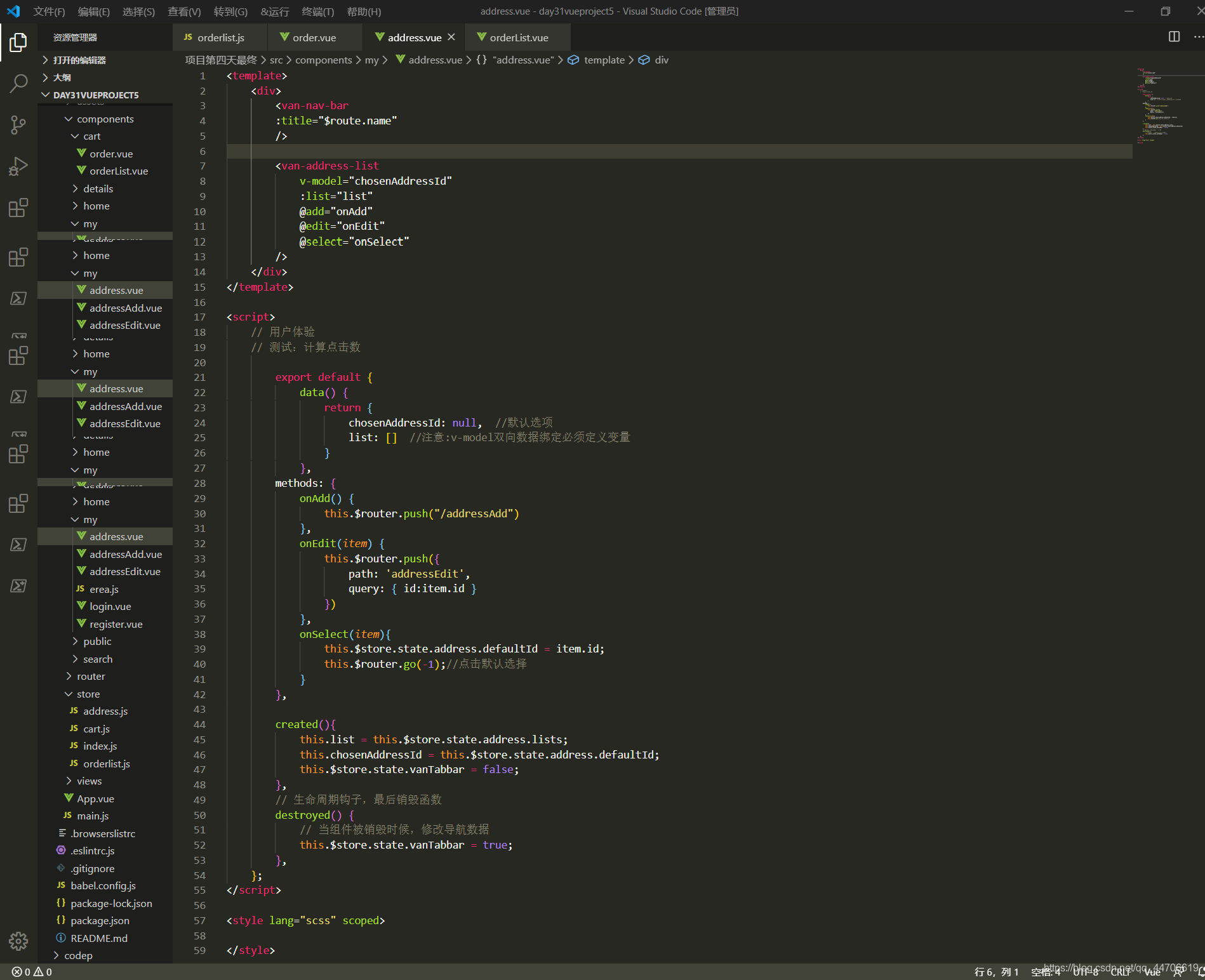 其次,增加地址操作,相对简单,传到vuex,在vuex以数组长度为他生成一个id,
其次,增加地址操作,相对简单,传到vuex,在vuex以数组长度为他生成一个id, 
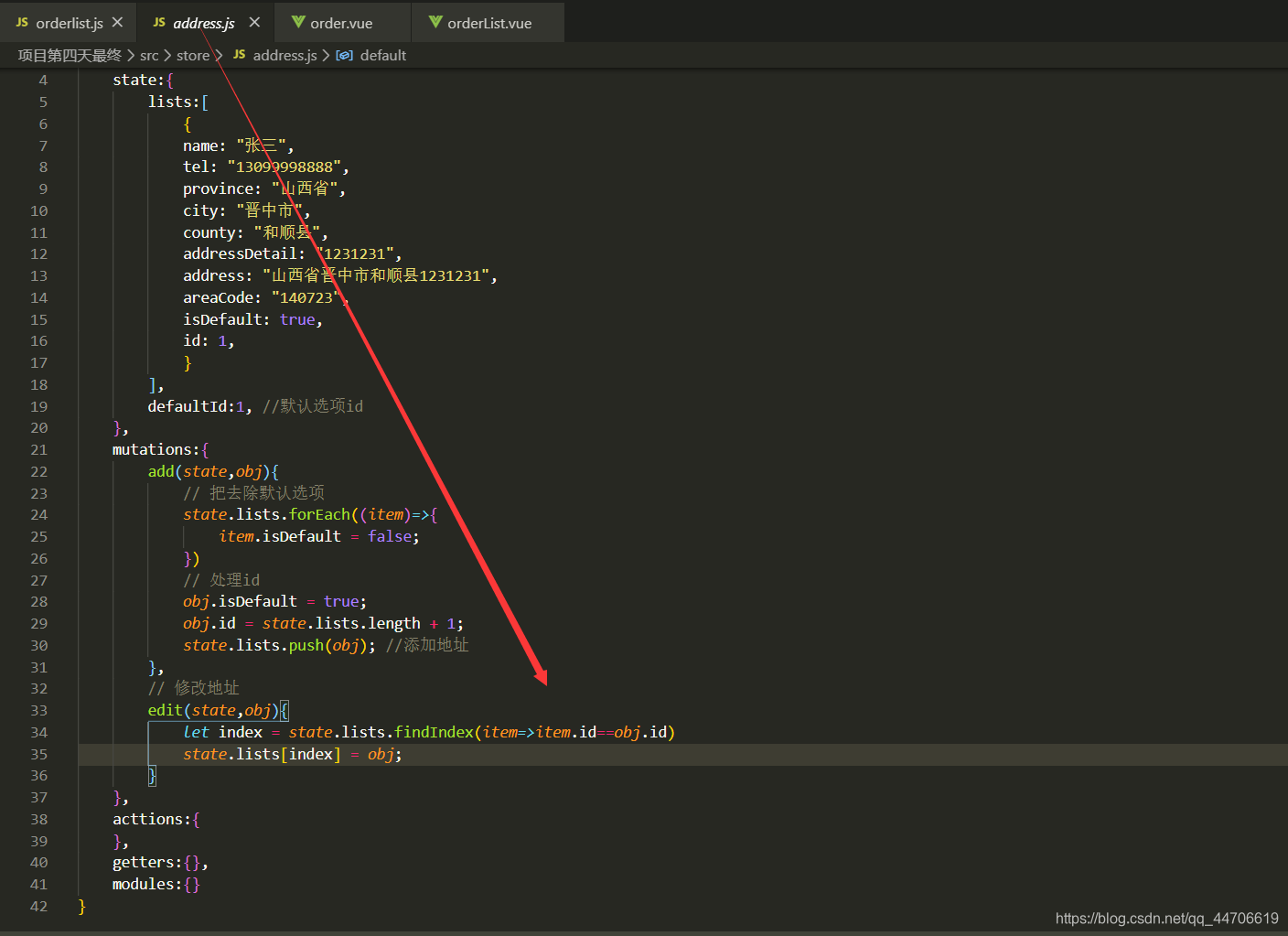
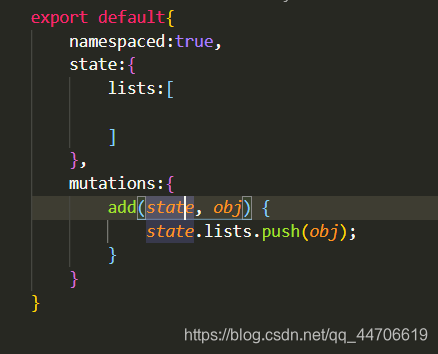 再次,有点拐弯的地址修改操作,点击对应的修改按钮,以路由传参到修改页面,在created中过去这个路由传的参,进行查询,放在页面上
再次,有点拐弯的地址修改操作,点击对应的修改按钮,以路由传参到修改页面,在created中过去这个路由传的参,进行查询,放在页面上  最后,地址删除,就没什么了
最后,地址删除,就没什么了 还有个在提交订单,支付之前选择地址的操作,这个时候要求,在点击地址的时候,会拿到这个订单的id,用于传去提交订单页,查询出来放在地址处,在进行支付操作

转载地址:http://gdgwz.baihongyu.com/
你可能感兴趣的文章